



Three objectives should ideally be met for an admirable outcome.
The first objective is - Enough evidence to back up the Motivation to work on it…if the work fails to convince us? Then maybe there are better options to spend our time on ;)...So, let's first answer
WHY & WHAT IS KAFKA?
As the definition for Kafka goes, it’s an Event streaming platform. But, what are events? In databases, nouns as in static data and their properties are stored but what we need is to store the changes on those nouns when certain events take place like sensor data, clicks on a website, and so on. So, storing events can give us deeper insights into the data, as we know what happened in the past and what actions can be performed on it now.
Like any other event streaming platform, Kafka gets the data from a source and provides functionality to process the data, then the processed data can be accessed from the sink which delivers topic data to other systems. So, is Kafka an advanced database that stores events data? Yes, you could say that, as it provides features such as stream history, scalable consumption, high availability, and scalability.
To understand how these advantages come into the picture, let us understand the lingo of Kafka.
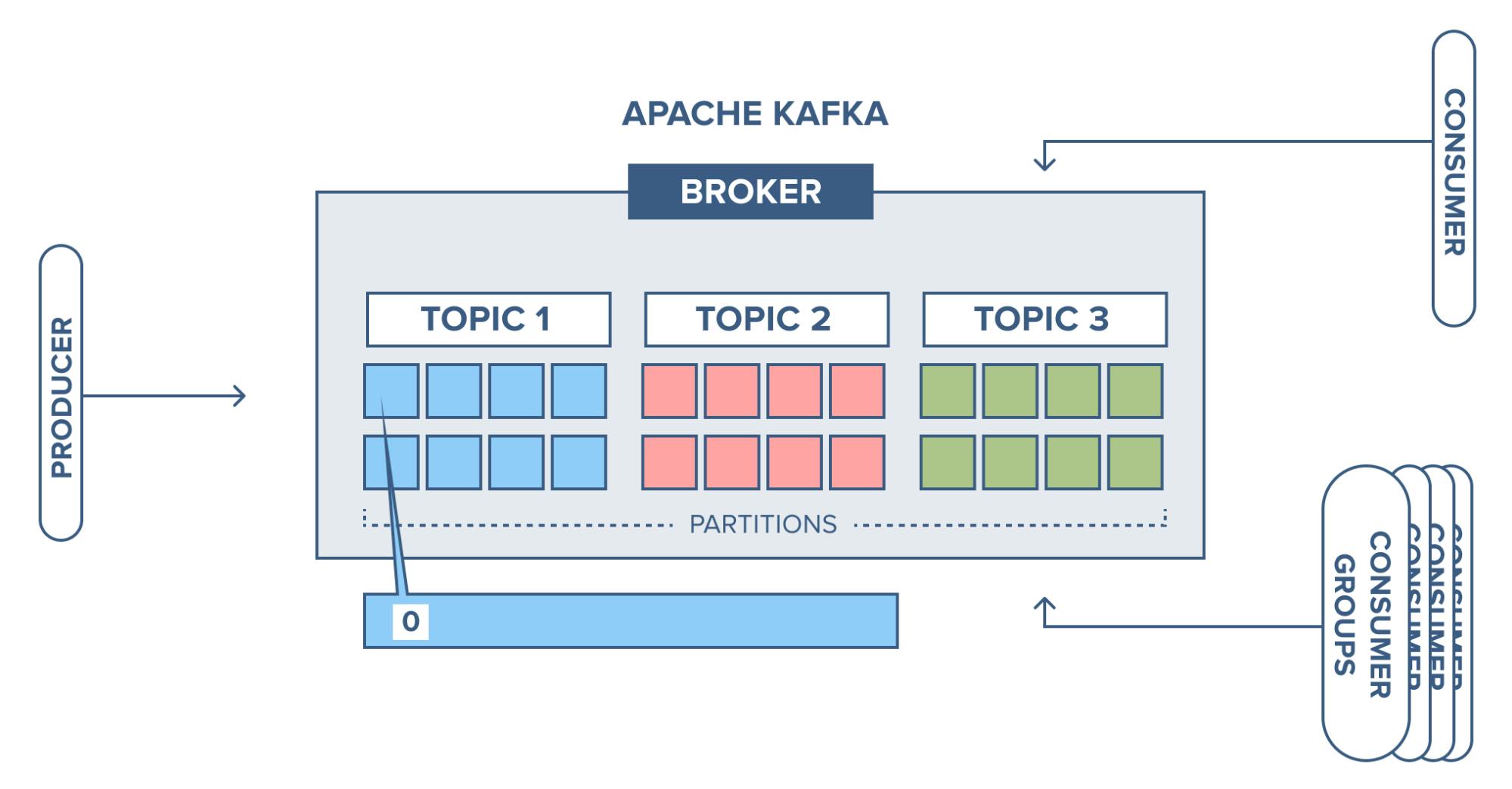
All the data is stored in topics - think of it as tables, with partitions - for splitting the work of storing, writing, and message processing among the nodes, as key-value pairs. The number of partitions for each topic should be specified - as a rule of thumb, ten partitions and Kafka makes sure to equally distribute the data among them in a round-robin fashion. Multiple partitions are needed for parallel read/writes for the consumers.
Each partition can have multiple key-value pairs, each pair is given an offset, which acts as a unique identifier of the record and separates each of them inside a partition. This is useful to keep track of the current consumer position.
These topics are present in containers called brokers. There can be multiple brokers with the replication of the topics in them. Ideally, it's a good practice to have three or more brokers. This duplication is useful for improving the reliability and availability, as, if one broker goes down, there are other brokers which can supply the same information.
For a particular topic and partition, there would be a leader who reads/writes from topics, others are followers, they sync with the leader. To admin these brokers and topics Kafka uses Zookeeper.
The producer publishes the events into Kafka and the consumer subscribes to the events from Kafka. This shows that the producer and consumer parts are decoupled as in there is no direct communication between them, the only connection is through topics.
Done with the theory! Now comes the showstopper coding section, which is our second objective.
Kafka has great developer docs and a huge community, which makes it increasingly easy to set it up, work, and start playing around with it. One can follow the official docs to set up Kafka.
I used docker to work with Kafka. I'll explain more about how I set Kafka up using docker in my next blog.
The last and the final objective - Acceptance of this new member into our everyday projects. Kafka has a feature - connect, which is an open-source component of Kafka that helps in connecting external source streams to Kafka and Kafka data to external systems through the sink. Kafka connect makes this external interaction possible through its connectors, which are available at confluent hub.
I made my first project by connecting MongoDB to Kafka producers and consumers. example
An interesting video which I referred.
That's all for this blog.
This is my first blog, any feedback is appreciated.